Hazelcast queues are not partitioned
Weak documentation
There. I said it, just in case you were looking for answers in the documentation and was coming up empty handed.
First of all, I like Hazelcast; it has a simple API, can be embedded in your application and works out of the box when you need to distributed data structures across processes or machines.
So how do the queues work in Hazelcast?
Based on the documentation on their forum, I think the following applies:
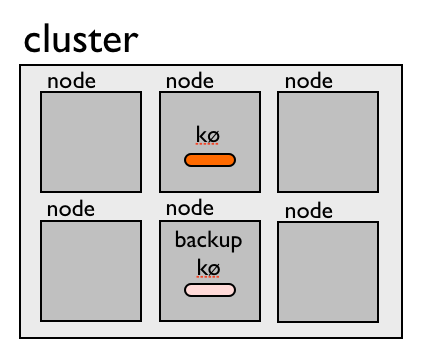
- A queue exists only on a single node in a cluster
- A queue may have backups on other nodes
- The client code is oblivious to which node owns the queue
- There is no guarantee of the processing order of messages on the queue
- Since the queue exists on a single node in its entirety, you can't increase the maximum size of the queue by scaling horizontally
- Messages can only be consumed one by one in a transaction.
- If you want to consume messages in bulk, you can choose between bad performance or potentially loosing messages
- A queue can be persisted if you implement the persistence yourself, typically to a central repository.
Here is an example of a cluster with a single queue and a backup
A trick you can do to scale the size of a queue is to stripe it, i.e create several queues that represents a single queue. Then you write to each of the queues in a round-robin style, and poll from all the queues. Obviously not a very scalable solution.
Stuff I'm still uncertain about:
- How does Hazelcast decide which node is responsible for a given queue?
- How is the performance affected when the number of reads increases?